祝贺课题组博士生景彦昊论文被多媒体领域旗舰期刊ACM TOMM接收
近日,课题组最新研究成果“HTMA-CL: A Hierarchical Tokenization and Multiscale Attention Framework for Compressive Domain Multimedia Inference”被多媒体领域旗舰期刊ACM Transactions on Multimedia Computing, Communications, and Applications(TOMM)正式录用接收。
压缩感知(Compressed Sensing,CS)提供了一种高效获取压缩信号的机制,并能从较少的压缩样本中高质量重建原始信号。CS理论突破了奈奎斯特采样定理对原始信号采样率的限制,通过高效的压缩大大降低存储空间需求和传输带宽开销,极大的促进了其在成像中的应用。尽管实现高质量的信号重建是压缩感知最关心的问题,但许多应用的重点是直接从测量值中进行高级语义理解,而不是精确的重建。例如,在医学图像分割和军事图像检测中,由于私人或机密信息泄露的重大风险,不建议进行信号重建。在模型训练和推理过程中,直接使用测量值进行推理也可以起到数据加密的作用,因为除非确切知道测量值,否则很难恢复原始信号。因此,直接从测量值实现推理任务具有重要意义。压缩学习(Compressed Learning,CL)集成了压缩感知(CS)和机器学习(Machine Learning,ML),能够从很少的CS测量值直接推理。然而,现有的压缩学习方法要么严重依赖于基于超大规模数据集的预训练模型,要么只能在小规模数据集上执行相对简单的推理任务,这限制了它们在现实多媒体场景中的可扩展性。为了解决这些局限性,我们提出了一种名为HTMA-CL的高效压缩学习框架,用于实际的多媒体采集和边缘智能处理。HTMA-CL采用基于卷积神经网络的可学习采样来实现高分辨率图像的块压缩,显著降低了传输带宽和存储开销。分层标记化模块(HTM)与深窄Transformer模块(DNTM)联合渐进对测量值中的局部和全局依赖关系进行建模,从而直接在压缩域中进行准确推理。最后,构建了多种任务头,用于执行如图像分类、语义分割等多媒体分析任务。实验表明,与其他压缩学习方法相比,本文提出的HTMA-CL获得了最佳性能,并且在压缩率为10%时,其性能与图像域方法几乎相当。进一步地,本文验证了所设计方法在物联网多媒体环境中对外部干扰的强鲁棒性。
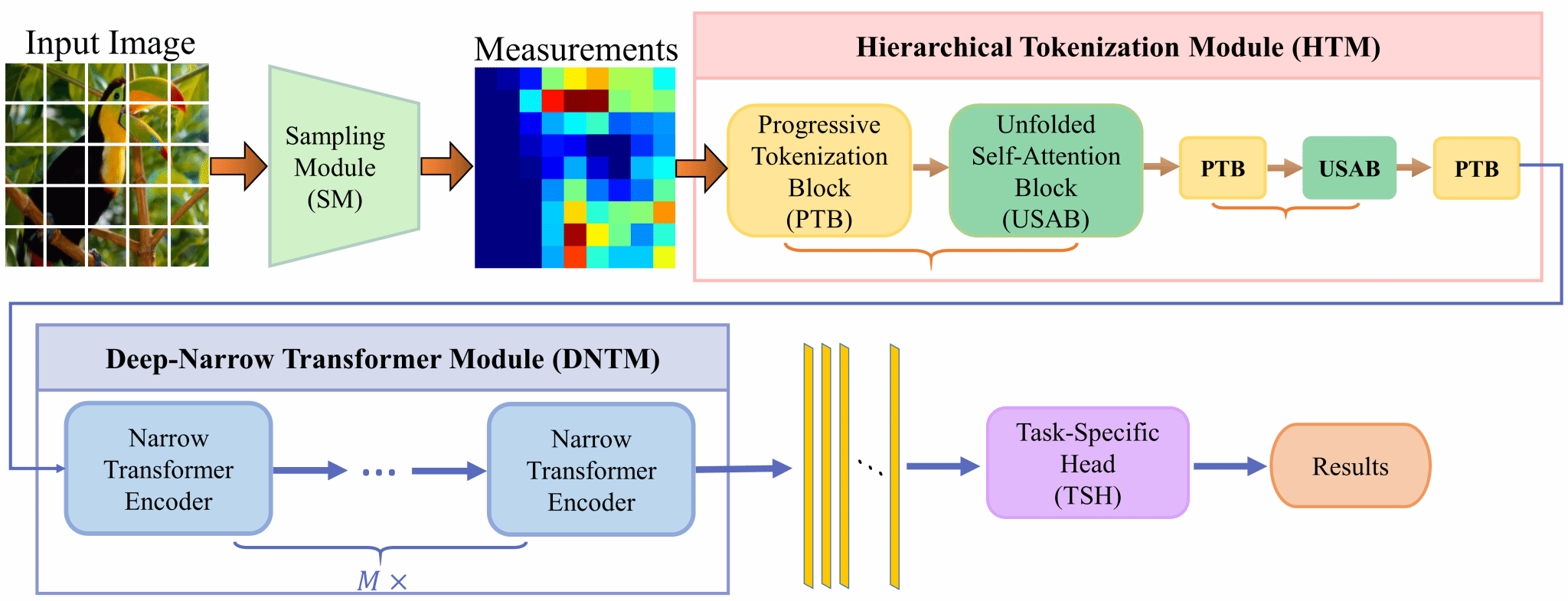
本文提出的HTMA-CL总体框架图
Table 3: Performance comparison in image classification on ImageNet-1K. Top-1 Acc represents the Top-1 (%) accuracy.
Method | Data Size | Params/FLOPs | Top-1 Acc (%) | |
Image domain | ResNet-101 [40] | 3×50176 | 45M/7.8G | 77.41 |
ResNet-152 [40] | 3×50176 | 60M/11.6G | 78.33 | |
RepViT-M2.3 [44] | 3×50176 | 22.9M/9.1G | 82.50 | |
ViT-B-16 [19] | 3×147456 | 86M/49.3G | 81.10 | |
ViT-B-32 [19] | 3×147456 | 88M/12.3G | 78.76 | |
PVT-Large [41] | 3×50176 | 62M/9.9G | 81.71 | |
DeiT-B [30] | 3×147456 | 86M/49.4G | 83.12 | |
EAPT-S [42] | 3×50176 | 39M/6.5G | 82.90 | |
SwiftFormer-L3 [43] | 3×50176 | 28.5M/8.1G | 83.00 | |
KAT-S [46] | 3×50176 | 22.1M/4.4G | 81.20 | |
Vim-S [45] | 3×50176 | 26M/- | 80.30 | |
Mamba®-S [47] | 3×50176 | 28M/- | 81.40 | |
VRWKV-S [48] | 3×50176 | 23.8M/4.6G | 80.10 | |
Token-based | SeiT [26] | 32×784 | 86M/16.8G | 74.00 |
SeiT++ [27] | 32×784 | 103M/11.0G | 77.80 | |
Compressive domain | VCL-T-10 [25] | 3×14745 | 589M/50.8G | 67.59 |
VCL-T-1 [25] | 3×1474 | 136M/49.6G | 59.89 | |
MCL-T-10 [25] | 3×14770 | 87M/49.4G | 74.07 | |
MCL-T-1 [25] | 3×1477 | 86M/49.3G | 68.92 | |
TransCL-16-10 [25] | 3×14745 | 86M/49.3G | 78.93 | |
TransCL-16-5 [25] | 3×7372 | 86M/49.3G | 77.52 | |
TransCL-16-2.5 [25] | 3×3686 | 86M/49.3G | 75.21 | |
TransCL-16-1 [25] | 3×1474 | 86M/49.3G | 73.65 | |
HTMA-CL-14-10 | 3×14745 | 21M/27.3G | 81.48 | |
HTMA-CL-14-5 | 3×7372 | 21M/27.3G | 80.89 | |
HTMA-CL-14-2.5 | 3×3686 | 21M/27.3G | 79.79 | |
HTMA-CL-14-1 | 3×1474 | 21M/27.3G | 76.32 | |
Table 5: Performance comparison in semantic segmentation on Pascal Context, Cityscapes and ADE20K
Dataset | Method | Data Size | Params/FLOPs | mIoU (%) | |
Pascal Context | Image domain | PSP [34] | 3×223729 | 73M/246G | 47.80 |
APC [50] | 3×262144 | 76M/282G | 54.70 | ||
GFF [52] | 3×262144 | 141M/811G | 54.20 | ||
SETR [29] | 3×230400 | 309M/281G | 47.70 | ||
SwiftFormer-L3 [43] | 3×230400 | 28.5M/37G | 51.30 | ||
RepViT-M2.3 [44] | 3×230400 | 23M/42G | 49.43 | ||
Token-based | SeiT [26] | 32×784 | 86M/16.8G | 45.61 | |
SeiT++ [27] | 32×784 | 103M/11.0G | 48.43 | ||
Compressive domain | TransCL-16-10 [25] | 3×22950 | 309M/281G | 39.29 | |
TransCL-16-5 [25] | 3×11475 | 309M/281G | 35.83 | ||
TransCL-16-2.5 [25] | 3×5625 | 309M/281G | 27.08 | ||
TransCL-16-1 [25] | 3×2250 | 309M/281G | 12.60 | ||
HTMA-CL-24-10 | 3×22950 | 64M/121G | 49.81 | ||
HTMA-CL-24-5 | 3×11475 | 64M/121G | 49.34 | ||
HTMA-CL-24-2.5 | 3×5625 | 64M/121G | 48.26 | ||
HTMA-CL-24-1 | 3×2250 | 64M/121G | 45.03 | ||
Cityscapes | Image domain | PSP [34] | 3×508369 | 73M/554G | 78.50 |
CCNet [51] | 3×591361 | 71M/698G | 80.20 | ||
GFF [52] | 3×746496 | 141M/2305G | 80.40 | ||
SETR [29] | 3×589824 | 309M/818G | 75.82 | ||
SwiftFormer-L3 [43] | 3×589824 | 28.5M/95G | 75.79 | ||
RepViT-M2.3 [44] | 3×589824 | 23M/107G | 75.38 | ||
CSFNet-1 [54] | 3×524288 | 11M/47G | 74.73 | ||
Token-based | SeiT [26] | 32×784 | 86M/16.8G | 72.33 | |
SeiT++ [27] | 32×784 | 103M/11.0G | 75.19 | ||
Compressive domain | TransCL-16-10 | 3×58752 | 309M/818G | 75.93 | |
TransCL-16-5 | 3×29376 | 309M/818G | 75.28 | ||
TransCL-16-2.5 | 3×14400 | 309M/818G | 72.88 | ||
TransCL-16-1 | 3×5760 | 309M/818G | 66.75 | ||
HTMA-CL-24-10 | 3×58752 | 64M/330G | 76.62 | ||
HTMA-CL-24-5 | 3×29376 | 64M/329G | 75.81 | ||
HTMA-CL-24-2.5 | 3×14400 | 64M/329G | 74.97 | ||
HTMA-CL-24-1 | 3×5760 | 64M/329G | 71.46 | ||
ADE20K | Image domain | PSP [34] | 3×223729 | 73M/246G | 44.94 |
GFF [52] | 3×262144 | 141M/811G | 45.33 | ||
APC [50] | 3×331776 | 76M/357G | 45.38 | ||
SETR [29] | 3×262144 | 309M/316G | 41.91 | ||
EAPT-S [42] | 3×262144 | 76M/1123G | 47.70 | ||
SwiftFormer-L3 [43] | 3×230400 | 29M/42G | 43.90 | ||
RepViT-M1.5 [44] | 3×230400 | 14M/24G | 43.60 | ||
PoolFormer-M48 [53] | 3×262144 | 77M/121G | 42.70 | ||
Token-based | SeiT [26] | 32×784 | 86M/16.8G | 39.00 | |
SeiT++ [27] | 32×784 | 103M/11.0G | 43.20 | ||
Compressive domain | TransCL-16-10 | 3×26112 | 309M/316G | 41.90 | |
TransCL-16-5 | 3×13056 | 309M/316G | 40.30 | ||
TransCL-16-2.5 | 3×6400 | 309M/316G | 38.48 | ||
TransCL-16-1 | 3×2560 | 309M/316G | 34.77 | ||
HTMA-CL-24-10 | 3×26112 | 64M/138G | 43.66 | ||
HTMA-CL-24-5 | 3×13056 | 64M/138G | 43.60 | ||
HTMA-CL-24-2.5 | 3×6400 | 64M/138G | 42.01 | ||
HTMA-CL-24-1 | 3×2560 | 64M/138G | 37.98 | ||

不同数据集上语义分割的视觉比较
(a) (b)
(c) (d)
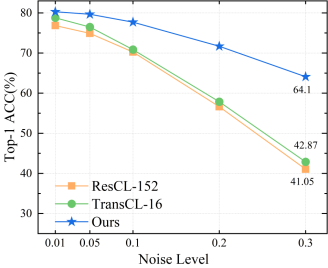
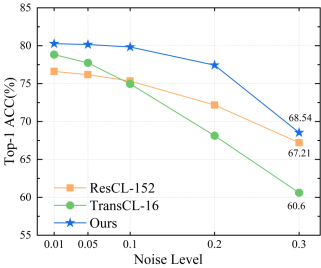
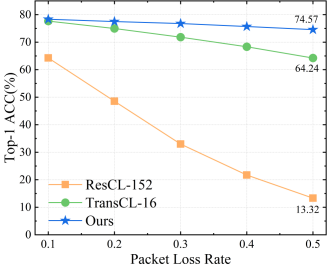
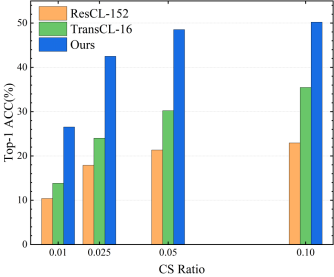
本文提出的HTMA-CL和其他模型的鲁棒性比较。(a)在原始图像中添加噪声;(b)向测量值中添加噪声;(c)不同丢包率;(d)数据传输顺序错误。
论文第一作者为博士生景彦昊,通讯作者为武相军教授。
ACM Transactions on Multimedia Computing, Communications, and Applications (ACM TOMM)是ACM多媒体特别兴趣小组 (SIGMM)的旗舰出版物,多媒体领域国际一流刊物,被中国计算机学会(CCF)认定为B类国际学术期刊。该刊创刊于2005年,出版周期为Quarterly,最新影响因子6.0,在 JCR 分区中位列 Q1 区。该期刊专注于多媒体计算(I/O设备、操作系统、存储系统、流媒体中间件、连续媒体表示、媒体编码、媒体处理等)、多媒体通信(实时-时间协议、端到端流媒体、资源分配、组播协议等)和多媒体应用(数据库、分布式协作、视频会议、3D虚拟环境等)方面的研究。

